Sentiment analysis with textblob

Sentiment analysis is the art of training an algorithm to classify text as positive/negative.
Follow along to build a basic sentiment analyser which is trained on twitter data.
We would need the textblob python package for this, which can be installed by executing: pip install textblob.
And, then you should run the following to download the necessary NLTK’s english corpus:
python -m textblob.download_corpora
Let’s import the packages we need:
from textblob import TextBlob
from textblob.classifiers import NaiveBayesClassifier
from textblob.sentiments import NaiveBayesAnalyzer
from textblob import Blobber
import pandas as pd
import seaborn as sns
%matplotlib inlineWe will use the STS Gold tweet dataset for training the Naive Bayes classifier. The tweets in this dataset are already annotated with its positive and negative polarity. STS Gold tweet data set was selected from the several available based on several suggestions which can be found in this paper.
Once you have downloaded the STS Gold dataset, please unzip it and place “sts_gold_tweet.csv” file in the current folder. Then:
#read the file
data = pd.read_csv("sts_gold_tweet.csv", sep=";", encoding="utf-8").drop('id', 1)
# replace 4 with 'post' and 0 as 'neg' in 'polarity' column
data['polarity'] = data.replace({4: 'post', 0: 'neg'})
# convert the data into a list
data = data[['tweet', 'polarity']].values.tolist()
L = len(data)
train_index = int(0.60 * L)
# split the data into a train and test data
train, test = data[:train_index], data[train_index: ]Now, let’s train the Naive Bayes Classifier on this training data. (P.S: on a 8GB RAM laptop, it took a good portion of an hour to train!)
cl = NaiveBayesClassifier(train)
cl.accuracy(test)To know the sentiment of a text, pass it to the TextBlob function and use it’s sentiment property to know its positivity and negativity.
blob = TextBlob("The beer is very good.", classifier=cl)
blob.sentiment
Out[65] : Sentiment(polarity=0.9099999999999999, subjectivity=0.7800000000000001)Great! So looks like our classifier is ready.
Now, let’s pickle it and save ourselves some training time, later.
import pickle
pickled_classifier_file = open('sentiment_classifier.obj', 'wb')
pickle.dump(cl, pickled_classifier_file)
pickled_classifier_file.close()To load a classifier from a pickled object, use pickle.load:
cl = pickle.load(open('sentiment_classifier.obj', 'rb'))Now, let’s put this classifier to use against a real world data set. The MAGAtweets.csv data set which can be downloaded from here contains tweets about women’s march and the #MAGA hashtag. Feel free to use any other tweet data that you are comfortable with.
The
TextBlobclass trains the classifier each time it is executed. On this machine, it took 5 seconds per execution. Hence, we will useBlobberclass instead.
tb = Blobber(analyzer=NaiveBayesAnalyzer())
Loading the tweet data to be classified -
tweet_data = pd.read_csv("MAGAtweets.csv", encoding="utf-8")
tweet_data = tweet_data.sort_values('created_at')Classifying the tweets now -
tweet_data[['nb_sentiment', 'nb_pos', 'nb_neg']] = tweet_data.text.apply(lambda v: pd.Series(tb(v).sentiment))
tweet_data.head()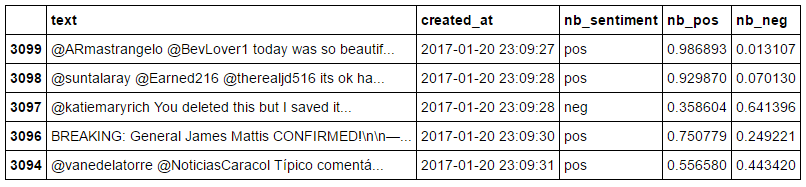
Let’s try doing the same with textblob’s in-built Pattern analyser -
tb = Blobber()
tweet_data[['pattern_polarity', 'pattern_subj']] = tweet_data.text.apply(lambda v: pd.Series(tb(v).sentiment))
tweet_data['pattern_pos'] = tweet_data.pattern_polarity.abs()
tweet_data[['pattern_pos', 'nb_pos']].hist()Observe the difference in the results -
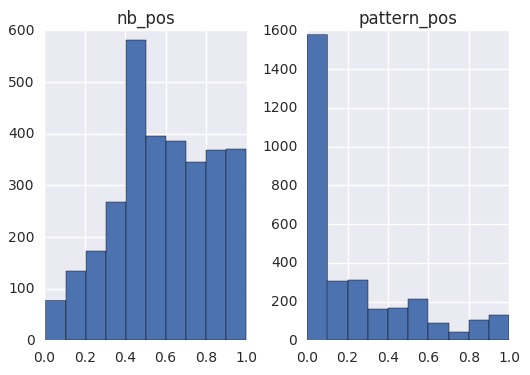
P.S: textblob is just one of the packages available in Python that can be used to perform sentiment analysis. Other capable packages that we know of would be - nltk, scikit-learn, VADER.
