Linear regression internals
Linear regression can be described as fitting a straight line through a set of given points. It is best used when you are sure that the points are laid out in a linear fashion. Though, the description of it may sound simplistic, the calculation of the regression coeffecients i.e. $ \beta_{0} $ and $ \beta_{1} $ in
$ \hat y_{i} = \beta_{0} + \beta_{1}x_{i} $ requires us to jump through a few hoops to derive it. So let’s get started.
Deriving the regression coeffecients
The distance of the line from each of the data points is called the error or the residual. A residual sum of squares $ RSS $ or $ SSE ^ 2 $ can be described as :
$ SSE^2 = \sum_{i=1}^{n}(y_i - \hat{y}{i} )^2 = \sum{i=1}^{n}(y_i - (\beta_{1}x_{i} + \beta_0))^2$
$ SSE^2 = \sum_{i=1}^{n}(y_i - \beta_{1}x_{i} - \beta_0)^2 $
The least squares regression line minimises the vertical distance between points and the line; which we can tune both regression coeffecients - $ \beta_{0}$ and $ \beta_{1}$ - to reduce square error towards zero. We start by calculating the value for $ \beta_{0} $ by taking the partial derivative of SSE with respect to $ \beta_{0} $.
(These quick tutorials to partial derivative and chain rule will help in case you want to refresh your memory of these concepts. Continuing with the derivation now.)
$ \frac{\partial SSE}{\partial\beta0} = 2\sum_{i=1}^{n}(y_i - \beta_{1}x_{i} - \beta_0)(-1) = 0$
$2\sum_{i=1}^{n}(y_i - \beta_{1}x_{i} - \beta_0)(-1) = 0 $
Removing the constants, we get -
$ - \sum_{i=1}^{n}y_i + \beta_{1}\sum_{i=1}^{n}x_{i} + \sum_{i=1}^{n}\beta_0 = 0$
$ \sum_{i=1}^{n}y_i - \beta_{1}\sum_{i=1}^{n}x_{i} = \sum_{i=1}^{n}\beta_0 $
The right hand side is a constant summed $ n$ times, which can be written as -
$ n \beta_{0} = \sum_{i=1}^{n}y_i - \beta_{1}\sum_{i=1}^{n}x_{i} $
$ \beta_{0} = \frac 1{n}(\sum_{i=1}^{n}y_i - \beta_{1}\sum_{i=1}^{n}x_{i}) $
Now, we will calculate the partial derivative $ SSE $ with respect to $ \beta_{1} $.
$ \frac{\partial SSE}{\partial\beta1} = 2\sum_{i=1}^{n}(y_i - \beta_{1}x_{i} - \beta_0)(-x_{i}) = 0 $
$ \sum_{i=1}^{n}(y_i - \beta_{1}x_{i} - \beta_0)(-x_{i}) = 0 $
$ - \sum_{i=1}^{n}(y_1x_{1}) + \beta_{1}\sum_{i=1}^{n}x_{i}^2 + \beta_0x_{0} = 0 $
Reorienting the components, we get -
$ \sum_{i=1}^{n}(y_1x_{1}) = \beta_{1}\sum_{i=1}^{n}x_{i}^2 + \beta_0\sum_{i=1}^{n}x_{i}$
This can be simplified as -
$ \sum(y_1x_{1}) = \beta_{1}\sum x_{i}^2 + \beta_0\sum x_{i} $
and, now, we substitute value of $ \beta_{0} $ in the above statement -
$ \sum(y_1x_{1}) = \beta_{1}\sum x_{i}^2 + (\frac 1{n}\sum y_i - \frac 1{n}\beta_{1}\sum x_{i})\sum x_{i} $
$ \sum(y_1x_{1}) = \beta_{1}\sum x_{i}^2 + \frac 1{n}\sum y_i \sum x_i - \frac 1{n}\beta_{1}(\sum x_{i})^2 $
Moving $ \beta_{1} $ terms to one side,
$ \beta_{1}(\sum x_{i}^2 - \frac 1{n} (\sum x_{i})^2) = (\sum x_{i}y_{i} - \frac 1{n}\sum y_{i}\sum x_{i})$
$ \beta_{1} = \frac {\sum x_{i}y_{i} - \frac 1{n}\sum x_{i}\sum y_{i}} {(\sum x_{i}^2 - \frac 1{n} (\sum x_{i})^2)}$
$ \beta_{1} = \frac {cov(x, y)}{var(x)}$
We now have both regression co-effecients :
$ \beta_{1} = \frac {cov(x, y)}{var(x)}$ and
$ \beta_{0} = \frac 1{n}(\sum_{i=1}^{n}y_i - \beta_{1}\sum_{i=1}^{n}x_{i}) $
Implementing linear regression from scratch
We can now use these derivations in a Python function to calculate the fitted regression coeffecients.
First off, let’s put these derivations down in a python function.
import pandas as pd
from matplotlib import pyplot as plt
def estimate_coeffecients(x, y):
# length of the arrays, assuming both x and y are of the same length
n = pd.np.size(x)
x_sum = pd.np.sum(x)
y_sum = pd.np.sum(y)
# numerator to the B1 coeffecient
SS_xy = pd.np.sum(x*y) - (x_sum * y_sum)/n
# denominator to the B1 coeffecient
SS_xx = pd.np.sum(x * x) - (x_sum ** 2)/n
beta_one = pd.np.divide(SS_xy, SS_xx)
# using the B1 coeffecient in B0 calculation
beta_zero = pd.np.mean(y) - beta_one * np.mean(x)
return beta_zero, beta_one
For the input data set, let’s use a subset of real data. We will use the closing value from the 3 month period starting on 1st May 2003 to Aug 2003 of the TATA MOTORS stock.
df = pd.read_csv("TATAMOTORS.BO.csv")
data = df.set_index('Date')['Close'].loc['2003-05-01': '2003-08-01']
data = data.reset_index(drop=True)
_ = data.plot()
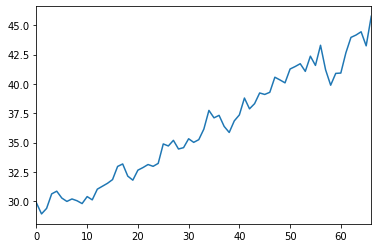
We have reset the date index of the data set to get a numerical index, instead.
data = data.reset_index().rename(columns={'index': 'x', 'Close': 'y'})
data.head()
| x | y | |
|---|---|---|
| 0 | 0 | 29.860500 |
| 1 | 1 | 28.927401 |
| 2 | 2 | 29.396900 |
| 3 | 3 | 30.632900 |
| 4 | 4 | 30.862900 |
We will pass the data to the plotting function below as an numpy arrays.
def plot_regression(x, y):
b0, b1 = estimate_coeffecients(x, y)
print("Regression coeffecients are : b0 = {:.2f}, b1 = {:.2f}".format(b0, b1))
plt.figure(figsize=(11, 9))
plt.axes(frameon=False)
yhat = b0 + x * b1
plt.plot(x, y, 'grey', x, yhat, 'lightcoral')
return (b0, b1)
x = data.x.values
y = data.y.values
b0, b1 = plot_regression(x, y)
Regression coeffecients are : b0 = 28.44, b1 = 0.24

In the above function, we use the estimate_coeffecients function to get the regression coeffecients ($ \beta_{0} $ and $ \beta_{1} $) and use them as intercept and slope to draw the regression line (in red). We could verify our derivation and coefficients with statsmodels as shown below.
import statsmodels.formula.api as smf
model = smf.ols(formula='y ~ x', data=data).fit()
model.params
Intercept 28.443442
x 0.236638
dtype: float64
Evaluating the model
import seaborn as sns
plt.figure(figsize=(11, 9))
sns.pairplot(data, x_vars=['x'], y_vars='y', size=7, aspect=0.7, kind='reg')
/Users/fibinse/anaconda3/lib/python3.7/site-packages/seaborn/axisgrid.py:2065: UserWarning: The `size` parameter has been renamed to `height`; pleaes update your code.
warnings.warn(msg, UserWarning)
<seaborn.axisgrid.PairGrid at 0x1a22e2d6d8>
<Figure size 792x648 with 0 Axes>

For evaluating our model, we will first need to calculate and store all the predicted ($ \hat y $) values into our dataframe.
data.loc[:, 'yhat'] = data.x.apply(lambda v: b0 + b1*v)
data.loc[:, 'Residuals'] = data['yhat'] - data['y']
data.head()
| x | y | yhat | Residuals | |
|---|---|---|---|---|
| 0 | 0 | 29.860500 | 28.443442 | -1.417058 |
| 1 | 1 | 28.927401 | 28.680080 | -0.247321 |
| 2 | 2 | 29.396900 | 28.916718 | -0.480182 |
| 3 | 3 | 30.632900 | 29.153356 | -1.479544 |
| 4 | 4 | 30.862900 | 29.389994 | -1.472906 |
Residual plots
The linear regression model assumes that there is a straight line relationship between the predictor variable ($ x $) and the target variable ($y$). You can verify this by plotting the residuals ( $ \hat y_{i} - y_{i}) $ ) against $x$.
import seaborn as sns
_ = sns.pairplot(data, x_vars=['x'], y_vars='Residuals', height=4, aspect=1.1, kind='reg')

The zero position on the y-axis is where we would love all our residuals to be on. That would mean that there is no difference between our prediction and actual values. A residual plot which is centered / clustered around $ y=0 $, is balanced on the $ +y $ and $ -y $ range and has no discernible patterns indicates a well-fit model. Here are some simulated residual plots that do not meet these conditions.
temp = data.copy().drop(['y', 'yhat'], 1)
fig, axes = plt.subplots(1, 2, figsize=(10, 4))
# residuals with outliers
random_index = pd.np.random.randint(low=data.x.min(),
high=data.x.max(),
size=1)[0]
_ = temp.copy()
_.loc[random_index, 'Residuals'] = 30
__ = _.plot('x', 'Residuals', ax=axes[0], kind='scatter', title='Residuals with outliers')
# residuals with funnel shape
_ = temp.copy()
_.loc[:20, 'Residuals'] = pd.np.random.uniform(-1, 1, size=(21,)) * 0.3
__ = _.plot('x', 'Residuals', ax=axes[1], kind='scatter', title='Residuals with funnel shape')

A sharp funnel (shown on the right) indicates a non-constant variance in error terms or heteroskedasticity. (éteros, meaning “other” or “different” and skedánnymi, meaning “to scatter” ). Linear transformations like $ log(x) $, $ \sqrt{x} $ help to reduce variance in the input features and can aid in reducing spread of residuals.
This brings us to the end of the walkthrough of linear regressions. If you like it or would like more areas to be covered, please leave a comment.
